大家好,歡迎來到爬蟲的世界!本篇文章是Selenium系列文章的第二篇~~
本篇參考大量Selenium說明文件,節錄部分程式碼及作者自行使用Selenium套件時的心得經驗,對其函式使用做更多延伸及說明。
對動態網頁爬蟲第一篇文章有興趣的可以參考以下文章:動態網頁爬蟲第一道鎖 — Selenium教學:如何使用Webdriver、send_keys
本篇文章會依序介紹以下內容,讓大家可以依此打開動態網頁爬蟲第二道鎖,才能順利的利用Selenium進行動態網頁爬蟲。
- 定位網頁元素
- Selenium函式的使用規則
- Selenium函式八大選擇器的使用方法:id、classname、tagname、link_text、XPath 、css_selector
在撰寫程式碼抓取網頁元素之前,我們一定要先知道資訊「在哪裡」跟「怎麼抓」,以下先就如何定位網頁元素來做說明。
1. 定位網頁元素
使用WebDriver時要學習的最基本技術之一,就是「如何在頁面上查找元素」。WebDriver可以視為目前畫面中的網頁(將其變數命名為driver),而我們可以使用Selenium強大的find_element(s)方法來定位目前網頁(WebDriver)中的元素,如程式碼1所示。
如程式碼1所示,我們使用driver = webdriver.Chrome()可以開啟chrome網頁,網頁上方應會顯示「Chrome目前受到自動測試軟體控制。」的字樣,執行driver.get(default_url)後,可以前往特定網址,本篇文章以https://www.google.com.tw為例進行說明。
打開網頁檢視器(Windows系統:請按f12、macOS系統:請按option+command+c),會看到以下畫面,如圖一。旁邊內容包含了所有網頁上看得到的內容,也就是說,網頁上看得到的一定抓得下來!是不是很振奮人心呢!

點擊網頁檢視器上方的鼠標,如圖二所示,再點擊想要查找原始碼的網頁元素,就可以快速定位原始碼了!

當圖二的鼠標圖示成功轉為藍色時,我們在頁面上滑動應該會如同動畫一,當鼠標在網路原始碼上移動時,原始碼對應到的網頁區塊就會反藍!

將鼠標移至畫面上想要查看的網頁區塊並點擊,右方的網頁檢視器便會幫我們找到對應的網頁原始碼段落,如同動畫二所示!是不是很方便啊!大家可以嘗試看看不同網頁的結果!

2. Selenium函式的使用規則
Selenium函式的使用方法可以大致歸類為以下兩大原則,並互相搭配使用:
兩種函數:
- find_element:抓取符合條件的第一個項目,可搭配By方法。
- find_elements:抓取所有符合條件的項目,並回傳成list。
八種方法:(WebDriver提供的內建選擇器類型)
- ID = id
- CLASS_NAME = class_name
- NAME = name
- LINK_TEXT = link_text
- PARTIAL_LINK_TEXT = partial_link_text
- TAG_NAME = tag_name
- XPATH = xpath
- CSS_SELECTOR = css_selector
3. Selenium函式:八大選擇器的使用方法
先載入需要的套件,如程式碼2所示。
舉例來說,要抓取id為example的網頁元素,可以有以下四種方法,如程式碼3所示:
而要抓取classname為「example」的網頁元素,可以將程式碼改寫成這樣,如程式碼4所示:
以下將對 WebDriver提供的八種內建選擇器分別進行說明。
1. Id
假如要抓取圖中的網頁元素,id為「gsr」,如圖三所示。

我們可以使用ID的方法來找到id=”gsr”的網頁元素,如程式碼5所示。
執行完後會出現以下結果。find_element(By)方法會回傳另一個Selenium基本類型,即WebElement。
<selenium.webdriver.remote.webelement.WebElement (session=”d4de9095fa86aee9883f7c01c3f0b723", element=”35ebc8f8–2381–46b5-b32e-8bdebc65186a”)>若使用find_elements(抓取所有符合條件者)則會回傳成list。
引用「已找到」的網絡元素後,我們可以再使用此網頁元素來找到更小範圍的網頁元素,以此類推,如程式碼6所示:
執行完上述程式碼後一樣回傳WebElement。
<selenium.webdriver.remote.webelement.WebElement (session=”d4de9095fa86aee9883f7c01c3f0b723", element=”7fe8dafa-bd78–4a7b-801f-df37eeb18346")>其他函數的執行方法跟結果都大同小異,只是在於函數內容不同以及跟抓取所使用的屬性不同,因此,以下將會重點說明不同方法之間的差異。
2. Classname
我們可以發現圖四這一個網頁元素,同時擁有class及id屬性,上一部分我們使用了id來抓取,這次我們可以嘗試使用class屬性及classname選擇器來抓取同樣的網頁元素。
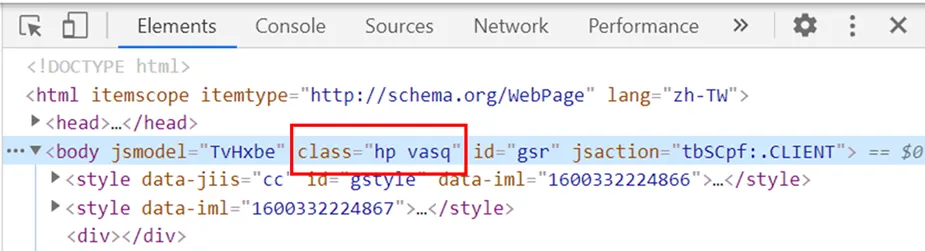
這裡特別注意一下:字串內有空格的話要改為「.」:「hp vasq」改為「hp.vasq」,如程式碼7所示。
3. Name
剛剛的網頁元素下方(子元素)可以看到有一個擁有name屬性的元素,如圖五所示,我們馬上來抓取看看吧!

Name的方法不太常用,不一定每個標籤都會有name屬性,但使用方法也是大同小異,如程式碼8所示。
4. LINK_TEXT
要使用LINK_TEXT方法,要知道href(帶有連結的屬性)對應的文字內容才行。例如:想獲取左上角「關於Google」的連結,如圖六所示,可以使用以下方法。

點擊網頁檢視器,將鼠標移至目標區域或按鈕並點擊,就會自動顯示該段的網頁原始碼了!如先前動畫二所示。
而我們可以看到這個網頁元素(HTML標籤為「a」),內含href、ping屬性,且包含一段黑色的顯示文字。這段文字(圖七紅框標示處)即是我們需要的LINK_TEXT內容!

我們需要的關鍵字即是「關於Google」的文字內容,而抓取WebElement的方法如同程式碼9所示:
5. PARTIAL_LINK_TEXT
類似於LINK_TEXT方法,但只需要部份文字即可,如程式碼10所示。
特別注意的是可能會將其他不需要的資訊一起抓下來,例如我們可以看到「關於 Google」旁邊的「Google 商店」也包含類似文字內容「Google」,如圖八所示。

而如圖九所示,我們也可以看到這兩個網頁元素確實都含有「Google」的文字內容。

假設我們想要抓取「Google商店」的網頁元素(位於第二項),使用PARTIAL_LINK_TEXT的選擇器,並使用「Google」作為關鍵字,就會抓到上一項「關於Google」的內容!
這時我們可以改用find_elements的函數來抓取所有符合條件的網頁元素,而find_elements的函數會將所有符合條件的網頁元素回傳成List,這時我們只要選擇第二個項目(Index為1)選取即可!如程式碼11所示。
6. TAG_NAME
這裡的tag即是HTML網頁標籤,是網頁檢視器裡紫色的字元部分,將網頁結構劃歸為各個階層,如圖十所示的head、body、style、div等。

而我們可以使用HTML標籤名稱(即TAG),來抓取網頁元素,如程式碼12所示。
但是使用TAG選擇器特別要注意的是,HTML標籤時常重複,因此TAG選擇器通常適用於抓取大框架的網頁元素再做細部搜尋。
7. XPATH
XPath是用於在XML文檔中定位節點的語言(可以想像網頁是圖書館,而各個網頁元素是書籍,XPath就有點類似於目錄編號,讓我們可以直接查找)。由於HTML可以是XML(XHTML)的實現,因此Selenium用戶可以利用這種強大的語言來定位網頁元素。
使用XPath最主要的原因是,當我們想要查找的元素沒有合適的id或name屬性時,可以使用XPath以絕對路徑(不建議使用)定位元素,也可以利用已知特殊id或name屬性的元素的相對路徑定位。
XPath包含來自HTML所有元素的位置(絕對路徑),因此,僅對網頁進行一點點調整就可能導致失敗(超級容易失敗,要不斷維護,非常不建議使用)。
因此,比較適當的使用方式是,通過查找具有id或name屬性的附近元素(最好是父元素),使用相對路徑來找到目標元素(因為通常局部細節的改動會少一點),並且可以減少程式碼的維護成本。
如何獲取網頁元素XPath
- 打開網頁檢視器,找到目標網頁元素的內容,如圖十一所示。

2. 在內容上點擊右鍵→Copy→Copy (full) XPath,獲取絕對或相對XPath。
在想要獲取XPath上的內容上點擊右鍵,如圖十二所示。

找到選單內的Copy清單,如圖十三所示。

點擊Copy XPath就可以將所需的 XPath複製下來做進一步爬蟲了,而Copy XPath下方的Copy full XPath也是同樣的概念(完整路徑),都可以用作XPath選擇器進行爬蟲!如圖十四所示。

3. 將複製下來的XPath貼上,如程式碼13所示,
8. CSS_SELECTOR
終於到了最後一種啦!可喜可賀!這一種是不一定每個人都需要(能用第1~6種就盡量用),但是功能非常強大的方法。
如果你想定位的網頁元素沒有唯一的ID(或其他),則推薦使用CSS SELECTOR來查找元素。XPath和CSS選擇器有類似的工作模式,但是使用起來是全部方法中最複雜的。
相對簡單的使用方式是:找到網頁元素的XPath再改寫成css格式。
- 「/」改寫成「>」
XPath: //div/aCSS: div > a
2. 「//」改寫成「 (空格)」
XPath: //div//aCSS: div a
3. 用id查找「#」
XPath: //div[@id=’example’]CSS: #example
4. 用classname查找「.」
XPath: //div[@class=’example’]CSS: .example
因為css selector算是比較進階的使用方法了,其他還有非常多強大的功能,有興趣者可以參考https://www.w3schools.com/cssref/css_selectors.asp,裡面有非常完整的css說明文件,基本上前面七個方法即可以滿足大部分網頁爬蟲的需求了。
大家可以自由嘗試合適的方法!!
以上就是本文關於Selenium的所有內容了!非常感謝大家用心的閱讀!
本文程式碼完整內容在此,祝大家爬蟲之路順順利利!
參考資料(皆為全英文內容):
1. Java, Python, C#, Ruby, JavaScript, Kotlin使用Selenium定位網頁元素的方法
作者:戴若竹(臺灣行銷研究特邀作者)、鍾皓軒(臺灣行銷研究有限公司創辦人)


您可能有興趣:
📢TMR為您量身打造「全方位數據課程」
👨🎓熱門Python程式語言結合全新商業思維,快來終生學習不間斷!
【TMR】 X 【 好學校】
👨💼Python商業全系列數位課程👨💼
#行銷人必學實用Python課程
《 Python 0到1 基礎商業數據分析實戰 》
💥 價格 :3188
👉 從0開始:手把手從頭學習,適合完全沒學過的學員
👉 商業應用全台最多:傳授市面上少見的Python實務應用
👉 網路輿情爬蟲演練:網路輿情商務爬蟲技法
👉 競品分析:競爭價值定位圖找出藍海策略
👉 貨架陳列視覺化:解析行銷策略及廣告預算配置方法
🛒 前往購買:https://hahow.in/cr/python0-1

《 顧客分類大師:Python x RFM 會員經營新觀點 》
💥 價格 :2388
🎯 Python X RFM最佳拍檔,輕鬆鎖定潛(錢)在顧客
不需要出門,在家也能學習專業課程,讓你擁有會員經營的新思維!
本課程以五個面向為您的企業,做更深入的健診:
👉 市場面:以最基本的顧客消費資料(頻率、購買次數),將現有顧客區隔分類。
👉 財務面:計算出在每個顧客身上所賺得毛利,在不同客群中的獲利。
👉 行銷面:藉由 RFM 的分析進行行銷預算重新分配。
👉 產品面:觀察在不同客群中,各個產品的銷售狀況。
👉 顧客回購面:分析顧客的購買週期後,進行精準推薦。
🛒 前往購買:https://hahow.in/cr/rfm-model

《 AI 行銷學:用 Python 機器學習創造商業新價值 》
💥 價格 :3888
👉 全台第一門Python機器學習線上課程
👉 教導你快速理解Logistic Regression, XGBoost, Random Forest商務機器學習模型。
👉 建構老闆或主管們看得懂的模型評估指標,讓精準行銷方案更容易被接受且推出
👉 如何利用機器學習找出消費者心中的重要變數及客樣貌與特徵,做到個體及總體的商品推薦?
👉 如何從數以萬計的消費資料中偵測可能的詐欺名單?
🛒 前往購買:https://hahow.in/cr/python-ml

#實用投資分析課程
《 用 Python 打造自己的股票小秘書 》
💥 價格 :4288
👉 打造自動推播機器人,趁著股市最近低迷,找出最適進場點
👉 「到價提醒」功能,大大提升投資便利性
👉 了解Python雲端服務架構,完整的專案流程
👉 孰悉No SQL資料庫操作,未來大數據的基礎
🛒 前往購買:https://hahow.in/cr/stock-secretary

#好學校企業百大課程之一:
《台科 EMBA 年年爆滿的一門 Word 課(A系列)》
💥 價格 :950
👉 系統性學習Office軟體功能,教您別人不知道的快捷鍵
👉 調整不受控制的行距與精準對齊排版
👉 一鍵轉換Word到Excel
👉 有效率處理企畫書、畢業論文、小組報告、公文等
🛒 前往購買:https://hahow.in/cr/tmr-word1

《 台科 EMBA 年年爆滿的一門 Word 課(B+C系列)》
💥 價格 :1,050
👉 傳授獨家快捷鍵字典
👉 分享好用的大綱模式,讓文章處理更有效率
👉 建立大綱模式、多層次清單、目錄與圖表目錄,掌握文件編輯規則
👉 優化文章的邏輯架構
🛒 前往購買:https://hahow.in/cr/tmr-word2

— — — — — — — — — — — — — — — — -
【TMR】 X 【工研院】
🏭工業4.0大數據智慧應用課程🏭
製程數據資料 X 資料科學,
為您開啟工業人工智慧領域的大門!
👉全球前十大智慧製程案例實戰
👉專業講師手把手帶您入門製程資料處理分析
👉課後完整模組心法讓您通通帶回家
💥價格 : 2,800
🏃趕緊手刀前往購買:https://bit.ly/39koNbn
— — — — — — — — — — — — — — — — -
2020課程地圖
💪 點我看更多

🏆 國內第一本行銷資料科學專書
💪 點我看書本資訊
🏆 國內第一本行銷資料科學 ” 實作 ” 專書
💪 點我看書本資訊
🏆國內第一本「股票小祕書」專書
附上購書網址~ 國外的朋友也可以使用博客來與金石堂的通路轉運到國外哦!

